
AI content detectors are tools designed to tell whether a piece of text was written by a human or generated by an AI.
They have become popular with the rise of large language models (LLMs) like ChatGPT, GPT-4, and others, as educators, publishers, and professionals seek ways to identify AI-generated text.
But how do these detectors actually work under the hood? This article provides a deep dive into the algorithms behind AI text detection, explaining key concepts like perplexity, burstiness, and entropy.
We’ll also explore how detectors are trained (using labeled datasets of human vs. AI writing), the different approaches (from statistical methods to AI classifiers), their accuracy limits (including false positives and negatives), and why modern models such as GPT-4 are especially challenging to detect.
By understanding the mechanics and limitations of AI content detectors, you can better interpret their results. (And if you’re curious, you can try our free AI content detector at detector-checker.ai – it’s instant, supports all languages, and requires no login.)
Key Concepts: Perplexity, Burstiness, and Entropy
Before diving into detection methods, it’s important to understand three core concepts often mentioned in AI text analysis: perplexity, burstiness, and entropy. These measures come from language modeling and information theory, and they help quantify how “predictable” or “random” a given piece of text is.
- Perplexity – In simple terms, perplexity measures how surprising or unexpected each word in a text is, according to a language model. An AI language model assigns probabilities to words; if the text uses very likely, predictable words in context, it has low perplexity, whereas an unusual or hard-to-predict word causes high perplexity. For example, consider the sentences: “For lunch today, I ate a bowl of soup.” versus “For lunch today, I ate a bowl of spiders.” The second sentence would have a much higher perplexity, since a language model does not often see “bowl of spiders” in normal usage. Essentially, perplexity is a measure of a text’s predictability or how “confused” a model gets when reading it. A lower perplexity means the text closely matches what the model expects (more predictable), and a higher perplexity means the text is more unpredictable or creative.
- Burstiness – This refers to the variation of perplexity throughout a passage. Burstiness measures how much the predictability fluctuates – in other words, does the text have parts that are very predictable and other parts that are very surprising? Human writing often contains bursts of unpredictability (a mix of common phrasing and occasional odd or creative choices), whereas AI-generated text can be more consistently average. Formally, burstiness can be described as the homogeneity of sentence lengths or structures and how they affect perplexity. If a text’s perplexity remains uniformly low from start to finish, it has low burstiness; if it spikes up and down (some sentences easy to predict, some very unpredictable), it has high burstiness. Human writing is typically thought to exhibit higher burstiness than AI writing, since humans might suddenly use an unusual word or style in parts of their text, while an AI tends to maintain a steadier tone and vocabulary probability.
- Entropy – In the context of language, entropy is a measure of randomness or disorder in the text. It’s closely related to perplexity: mathematically, perplexity is an exponentiated form of entropy. You can think of entropy as the average surprise per word. For example, if a language model has an entropy of 3 bits on a piece of text, that means each word is as uncertain as picking among 2^3 = 8 options – thus the model’s perplexity on that text would be 8. Lower entropy means the text is more predictable (less random), while higher entropy means more uncertainty. In practical terms, AI detectors that analyze entropy are looking at how rich or uniform the vocabulary and phrase choices are. Highly uniform, repetitive text has lower entropy, whereas text with a wide range of word choices has higher entropy. Entropy ties into perplexity because if a text has low entropy (very predictable words), it will yield low perplexity scores from a language model.
Understanding these concepts is crucial because many AI content detectors operate on the premise that AI-generated text is more predictable (low perplexity, low burstiness, lower entropy) than human-written text.
Human writing, coming from individual style and sometimes quirky word choices, might register as more irregular or surprising to a model (higher perplexity spikes and burstiness). These statistical signatures form the basis of certain detection algorithms, as we’ll see next.
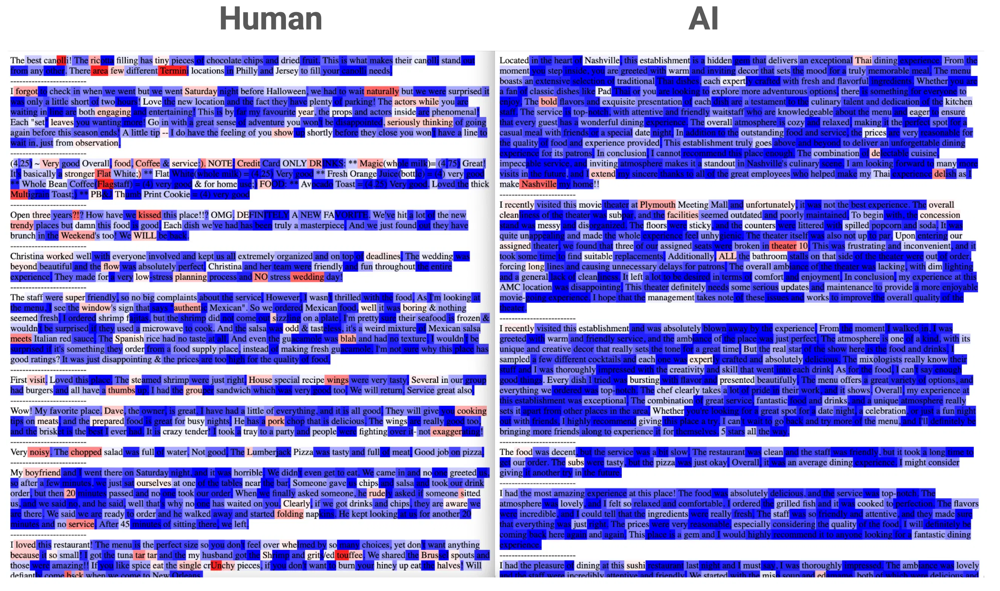
Visualization: An example of perplexity analysis on human vs. AI text. In the image above, a language model was used to highlight each word’s perplexity (low perplexity in blue, high perplexity in red).
The human-written text (left) shows occasional red spikes – some words or phrases are surprising to the model – indicating higher burstiness.
The AI-generated text (right) is almost entirely blue, meaning the text stays within a very predictable range. This illustrates the common pattern that human writing tends to have more variation in predictability, while AI writing often remains uniformly likely according to the model’s training.
How AI Detection Algorithms Work
Modern AI content detectors use a variety of methods to decide if input text is human or machine-produced. Broadly, these methods can be divided into three categories: statistical approaches, classifier-based approaches, and transformer-based approaches (often a subset of classifier methods, but leveraging deep learning). Let’s break down the differences:
Statistical Detectors (Perplexity-Based)
These methods rely on analytical metrics (like the perplexity and burstiness described above) rather than explicitly learning from examples. A statistical AI detector will typically use a language model (such as GPT-2 or another pretrained model) to evaluate the input text.
It calculates things like the text’s average perplexity and how much that perplexity varies. The assumption is that AI-generated text will have lower perplexity and lower burstiness on average than human text.
For instance, GPTZero – one of the early widely-used detectors – looks at each sentence’s perplexity and flags text as AI-written if perplexity stays consistently low (meaning the text is too predictable) and lacks the spikes a human-written piece would have.
Essentially, statistical detectors set thresholds: if a document’s perplexity score is below a certain cutoff (too regular) and burstiness is low, it’s classified as likely AI-generated. These methods are straightforward and don’t require a special training dataset – they leverage an existing language model as a reference.
However, they have notable limitations which we’ll discuss (e.g. they can mislabel any text that happens to be very predictable as AI, even if a human wrote it).
Classifier-Based Detectors (Supervised Machine Learning)
Classifier-based approaches treat the problem as a classic binary classification: given a piece of text, predict whether it’s “Human” or “AI”. To build such a detector, developers train a model on labeled examples of human-written and AI-written text.
This typically involves assembling a dataset – for example, collecting a large set of human articles or essays, and another set of AI-generated texts (from various models) – and then training a machine learning classifier to distinguish them.
Early examples include OpenAI’s GPT-2 output detector, which was a model trained on GPT-2 generated text vs. real text. OpenAI’s later AI Text Classifier (released in early 2023) similarly was a language model fine-tuned on pairs of human and AI texts on the same topics.
The classifier approach often uses a transformer model under the hood (since transformers are state-of-the-art in NLP), but the key is that it learns from data. The model might pick up on subtle cues that go beyond just perplexity – such as unusual phrasing, grammatical consistency, or other patterns – to make its prediction.
Classifier-based detectors can be more robust than a purely statistical threshold; they effectively learn the difference between human and AI writing style from examples.
However, training such models is challenging: they need a large and diverse dataset of AI outputs from different sources, otherwise a detector might only be good at catching the specific AI model it was trained on and fail on others.
Transformer-Based and Advanced Methods
This overlaps with classifier detectors, because most state-of-the-art classifiers are based on transformer architectures (like RoBERTa, BERT, or GPT themselves).
For example, the OpenAI GPT-2 detector model was a RoBERTa-based transformer fine-tuned on detecting GPT-2 outputs. Transformer-based detectors can also include zero-shot techniques proposed in research.
One notable example is DetectGPT, a 2023 academic method which didn’t require training on examples; instead, it analyzes the “curvature” of a text’s probability under a language model to decide if it’s AI-written.
In simple terms, DetectGPT checks how the likelihood of the text changes if you make small perturbations to it – the idea being that AI-generated text lies in a shallow probability “valley” of the model’s distribution.
Another example is a method called Binoculars which uses cross-perplexity (checking the text against two different models for consistency). These transformer-based approaches are generally more sophisticated ways to leverage language models for detection.
They still fundamentally rely on the fact that AI text statistically looks different from human text in a model’s eyes, but they try to be more model-agnostic or robust.
Additionally, companies like Turnitin and others have developed proprietary detectors that likely use ensembles of transformer models or multiple features.
In essence, transformer-based detectors often mean using a large neural network to either directly classify text or to generate rich metrics (beyond plain perplexity) for making a decision.
It’s worth noting that many commercial AI detectors combine approaches. For instance, a system might use a transformer-based classifier but also report a perplexity score or highlight areas of the text that look most AI-like.
In fact, “AI-generated text classifiers” is a general term that covers anything from a simple statistical test to a complex neural network – as long as it sorts text into “human or AI” categories. The trend in 2024-2025 is toward deep learning models (transformers) for detection, because purely statistical methods have shown weaknesses.
Research from Pangram Labs points out that while perplexity-based metrics capture something real about AI vs. human text, building a reliable detector for high-stakes use “requires more than a single statistic”. Next, we’ll see how these AI detectors are trained and what data they use.
Training AI Content Detectors (Datasets and Learning)
How do you teach a machine to spot AI-written text?
The supervised detectors (classifier-based) require training data. Typically, developers curate a dataset containing pairs of texts on the same topic – one written by a human, one by an AI – or generally a large collection of human examples and AI examples.
OpenAI’s team, for example, assembled a dataset for their AI text classifier by taking prompts and including a human-written response (from their sources like human demonstrations or human-written essays) and an AI-generated response to the same prompt.
By training on such pairs, the classifier learns to differentiate the style differences when content is about the same subject matter. They also drew human text from sources like the GPT model’s pretraining corpus (which is a broad mix of Internet text) to cover diverse writing styles.
The AI-generated portion of training data often comes from a mixture of contemporary models. For instance, a robust detector in 2023 would include outputs from GPT-3, GPT-3.5, GPT-4, maybe other models like Anthropic’s Claude or Google’s PaLM, etc. Including a variety is important – otherwise the classifier might just latch onto quirks of one AI model. OpenAI noted that their classifier was tuned to be more reliable by training on text from “a variety of providers”.
Likewise, academic datasets such as the GPT-2 Output Dataset released in 2019 contained hundreds of thousands of GPT-2 generated texts alongside real texts, to facilitate research into detection.
By exposing a model to many examples, it can learn generalizable features (for example, maybe it notices that AI text often overuses certain transition phrases, or that the vocabulary richness is different).
A challenge in training is avoiding bias. If the training data isn’t carefully curated, the detector might pick up on irrelevant correlations. A striking example was highlighted in a Stanford study (cited by Pangram Labs) which found that some detectors flagged non-native English writers as “AI” at higher rates.
This happens because essays by English learners tend to be simpler and more formulaic (lower complexity and thus lower perplexity) – ironically resembling AI-generated text in the eyes of these metrics. To mitigate this, some detector developers now include non-native writing samples in the training set to help the model recognize that style as human.
Similarly, Pangram Labs mentions they use deep active learning, continuously updating their model with new human text samples to improve accuracy over time.
It’s important to understand that statistical detectors (like pure perplexity tests) don’t “learn” from examples – they have no training phase where they get better with more data. They simply apply a fixed formula or threshold.
In contrast, classifier and transformer-based detectors can be improved and fine-tuned. For instance, if a new type of AI model appears and starts generating text with a slightly different style, a statistical detector might misfire (since it wasn’t calibrated for that style).
But a learning-based detector could be retrained or updated with some samples from the new model to adapt its internal parameters. This flexibility is a big reason why many experts advocate moving “away from perplexity and burstiness, and towards deep learning based methods” for detection.
Accuracy Limits and Common Challenges
No AI content detector is 100% accurate. In fact, the current generation of detectors come with significant limitations.
Users of these tools should be aware of false positives (flagging a human text as AI) and false negatives (missing an AI-generated text) – both of which can and do happen. Here are some of the key challenges and sources of error:
False Positives on Familiar Texts
Ironically, if a human-written text is too predictable or common, a detector might misclassify it as AI-generated. A famous case is the Declaration of Independence being flagged as AI by perplexity-based detectors.
Why? Large language models have seen that historical document so many times in training that they can predict every word with high confidence (low perplexity). To the detector, it looks algorithmically generated (all blue, no burstiness).
Similarly, Wikipedia articles – being common training data for AI – often come out as “too predictable” and can be false-flagged. In short, detectors can mistake widely published, formulaic, or repetitive human text for AI output, because AI models have effectively memorized those patterns.
Bias Against Certain Writing Styles
As mentioned, writing by non-native English speakers or students can sometimes get unfairly flagged. Such writing may use a limited vocabulary or simpler sentences (lower entropy and burstiness), which superficial detectors interpret as AI-like. Creative writing that uses very consistent style or repetitive phrasing might also trip up detectors.
Awareness of these biases is crucial – a detector’s score is not proof of intent. Developers are trying to address this by improving training sets and algorithms, but users should interpret results with caution, especially in high-stakes scenarios.
Difficulty with Short Texts
Most detectors struggle with short inputs (for example, a single sentence or a short paragraph). OpenAI explicitly warned that their classifier was “very unreliable on short texts (below 1,000 characters)”. The reason is simple: with little text, the model doesn’t have enough signal to judge the style.
A brief factual statement like “The sky is blue.” could be said by anyone (human or AI). Detectors typically need a longer sample to accumulate stylistic cues. So if you paste only a couple of sentences into an AI checker, take the result with a grain of salt.
Evasion by Paraphrasing or “Humanization”
It’s relatively easy to fool many AI detectors by making minor edits to AI-generated text. Paraphrasing tools or even a quick manual rewrite can raise the perplexity and burstiness, thus dodging the simple metrics.
OpenAI acknowledged that “AI-written text can be edited to evade the classifier”. Researchers and students have discovered lots of tricks: reordering sentences, swapping out words with synonyms, adding a bit of spelling or grammatical noise, etc., can reduce the detector’s confidence.
Some free tools (and ironically, AI itself) can rephrase AI text to make it read more human-like. Detector developers do try to catch up by retraining on these “attacked” texts, but it’s a cat-and-mouse game.
In fact, a March 2024 research paper documented how easy it was to bypass several classifiers by paraphrasing, and raised concerns about detectors incorrectly penalizing non-native English writers.
False Negatives on Advanced AI Text
As AI models become more sophisticated, their outputs more closely mimic human writing quirks. This means some AI-generated content slips past detectors entirely.
A detector might confidently label an AI-written essay as “likely human” if the essay doesn’t exhibit the telltale statistical signs the detector was trained on.
For example, GPT-4’s writing is generally more varied and nuanced than GPT-2’s or GPT-3’s, so using a detector calibrated on older model outputs can lead to misses.
In one informal experiment, educators found that longer essays from GPT-4 were much harder for detection tools to identify compared to GPT-3.5’s output (the detectors gave low AI probability for GPT-4 text). Simply put, newer models can outsmart older detection techniques.
Keeping Up with New Models
The AI landscape evolves quickly – new language models with different styles emerge, and detectors have to adapt. A perplexity-based detector has to choose a particular reference model (say, GPT-3) to compute perplexity.
If someone uses a different AI (say, Claude or a fine-tuned model), the perplexity might not accurately reflect its “humanness”. This model mismatch problem can yield inaccurate results. Likewise, a classifier trained on last year’s AI models might not recognize the signature of this year’s model.
Developers try to update detectors, but there can be a lag. As Pangram’s team noted, each new model release can “compound” the difficulty, and detectors tied to specific older models may “completely fumble” when faced with GPT-4 or other 2024–2025 models.
Given these challenges, it’s not surprising that OpenAI themselves retired their AI text classifier in July 2023 due to a “low rate of accuracy.” They reported it correctly identified only 26% of AI-written text in their evaluations, while incorrectly flagging human text 9% of the time. In a blog post, OpenAI admitted “it is impossible to reliably detect all AI-written text” with current methods.
This candid assessment underscores that AI detection has inherent uncertainty. Users of detectors should treat the results as one piece of evidence, not absolute proof. A sensible guideline is to use detectors as a prompt for further investigation rather than a verdict.
Why Modern Models like GPT-4 Are Harder to Detect
When GPT-3 came out, its writing, while fluent, still had some telltale signs – it could be overly formulaic or off in certain ways – making detection somewhat feasible.
Fast forward to GPT-4 and other state-of-the-art 2025 models, and the game has changed. GPT-4 is significantly harder to detect for several reasons:
More Human-Like Text
GPT-4 was trained on an even larger and more diverse dataset, with fine-tuning (including human feedback) to make its outputs more natural.
It tends to produce text with a good balance of creativity and coherence. This means GPT-4’s output often has higher entropy and burstiness than older AI models, closer to a human writer’s level.
Simple detectors that expected “robotic” consistency or simple vocabulary from AI are thrown off. For example, detectors that would flag a bland, repetitive essay might totally miss a GPT-4-written essay that includes humorous analogies, varied sentence lengths, and even a few typos or slang terms (which GPT-4 is capable of if it imitates certain styles).
Adaptive and Diverse Styles
New LLMs can mimic a wide range of writing styles, even injecting randomness when asked. A user might prompt GPT-4 to “write this in a casual tone with some quirks,” and the output will deliberately include more unusual word choices or sentence structures.
This intentional style variation can defeat detectors. Essentially, GPT-4 can pretend to be human by introducing the kind of imperfections or idiosyncrasies that detectors look for. By contrast, earlier AIs often had a more generic voice unless heavily directed.
Detectors Trained on Older Models
As mentioned, a lot of detection tools were built and tuned on data from GPT-2 or GPT-3 era outputs. GPT-4 is a different beast. Using an older model as the basis for perplexity calculations on GPT-4 text can give misleading results – GPT-4’s text might contain patterns that an older model finds surprising (high perplexity) even though it’s AI.
One research finding was that perplexity is relative: what’s low perplexity for GPT-2 might be high perplexity for GPT-4, and vice versa. So a detector needs updating to handle GPT-4’s distribution.
Many services in 2023 found that their accuracy dropped when users started inputting ChatGPT GPT-4 content – the detectors had to catch up with new training data.
Lack of Reliable Watermarks
There was a hope that AI models could watermark their outputs (i.e. embed a hidden signal in the text that an external checker could detect). OpenAI and others researched watermarking methods for GPT-4 and beyond, with some promising results in controlled tests.
In fact, OpenAI reportedly had a working prototype that was 99% effective at tagging GPT-generated text in a way that was robust to minor edits. However, this hasn’t been deployed in the wild. OpenAI held off on public watermarking partly due to concerns it might deter users or be seen as a liability.
Moreover, even the best watermark can be defeated if someone uses another AI model to paraphrase the text (a tactic which OpenAI noted makes circumvention “trivial for bad actors”).
As of 2025, GPT-4’s outputs are not watermarked by default, meaning detectors have to rely on the same old statistical or learned cues – which, as we’ve discussed, GPT-4 is adept at masking.
In summary, each new generation of AI makes the detection problem harder. Detectors are in an arms race with text generators. Just as spam filters had to evolve as spammers got more clever, AI content detectors must evolve to handle more advanced AI text.
This might involve using ensembles of models, more sophisticated features, or even meta-data analysis in the future.
There’s ongoing research into new techniques (for example, leveraging metadata or network-level analysis of AI usage), but at the text level, it’s a challenge.
It’s telling that some experts advocate shifting focus from trying to spot AI text to instead “verified provenance” – meaning, for instance, having AI models voluntarily tag their content or using cryptographic signatures to verify if text came from an AI.
However, until such systems are widespread, content detectors remain our main tool, imperfect as they are.
Conclusion: The Evolving Landscape of AI Text Detection
AI content detectors provide valuable insights into whether a text might be machine-generated, but they are not foolproof lie detectors. They work by analyzing statistical patterns and learned cues that often (but not always) differentiate AI writing from human writing.
We explored how concepts like perplexity and burstiness give a window into these patterns – AI text tends to be more predictably “average” in word choice, whereas human text shows more randomness and spikes of surprise.
We also saw that there are two broad approaches: one uses fixed algorithms and language model probabilities to flag AI text, and the other uses trained classifiers (often powered by transformers) to recognize AI-written text from examples. Each approach has its strengths and weaknesses.
Accuracy remains a big concern. False positives can harm trust – imagine wrongly accusing a student of cheating when they actually wrote their essay. False negatives mean AI-generated misinformation or spam might slip through undetected.
The current detectors do a decent job on straightforward AI outputs (for example, the raw output of ChatGPT in early 2023 could often be caught), but they struggle with seasoned models like GPT-4 or text that’s been lightly edited.
In fact, as we discussed, today’s advanced AI content is often virtually indistinguishable from human writing by any automated test. This doesn’t mean detection is hopeless – it means we must use these tools carefully and continue to improve them.
Looking ahead, developers are refining detectors by using larger and more representative datasets, employing deeper neural networks, and even exploring novel ideas like cross-model verification or metadata embedding.
There is also interest in cooperative solutions (like AI-generated text being accompanied by an identifier when it’s created, to make later detection easier). For now, if you use an AI content detector, use it as an aid rather than a final judge. Consider the context of the text and whether the detector’s output makes sense.
Lastly, if you’re curious about checking content yourself, feel free to try our own AI Content Detector on detector-checker.ai. It’s free to use, works with text in all languages, provides instant results, and never requires any login.
We designed it as a convenient tool to get a second opinion on your content’s origin. Like all detectors, it’s not infallible, but it’s continuously updated and tuned to the latest models.
As AI generation and detection technologies evolve, we remain committed to helping users navigate this new content landscape responsibly. Happy detecting!